
文本转TTS语音共存版(MultiTTS)v1.7.5.1 安卓最新版
时间:2026-06-23 21:20
大小:123.5M
系统:Android
语言:中文
时间:2026-06-23 21:20
大小:123.5M
系统:Android
语言:中文
可经与各种小说app及阅读软件搭配使用享受免费听书功能的一款语音引擎软件,multitts共存版是可以与官方版共存的版本,签名不一样,能同时安装使用,拥有丰富多样的ai语音包,无论是在线使用还是离线使用都可以,有需要或者想自己diy设置规则的朋友可以来试试,文本轻松转TTS语音工具。
文本转TTS语音共存版(MultiTTS)现已更新至v1.7.5.1安卓最新版。本次更新重点修复了部分机型上语音合成异常退出的问题,并优化了多引擎切换时的内存占用,合成速度提升约15%。功能方面,新增自定义语音缓存路径选项,方便用户管理存储空间;同时改进了引擎兼容性,现已支持同时加载多个第三方TTS引擎并智能调度。用户反馈中,多数好评认为新版朗读更流畅、多引擎共存体验更稳定;部分用户建议增加离线语音包批量下载功能,开发组已列入下一阶段计划。我们持续倾听声音,致力于让Android端语音合成更自由、更高效。
")
1、下载multitts和语音包
")
2、安装后右上角导入(没反应就重载)
")
3、左上角软件设置(如果卡就开转发器,不卡就不用管)
")
4、单击选声音(长按头像可调语速音调)
")
5、先准备好小说(txt文件)
6、左上角软件设置:开合成、转发器、文本解析→会自动在角色管理生成失配男失配女
7、回到声音列表,单击旁白,长按声音字母处选择为对话(各选择一个)
")
8、打开角色管理瞄一眼
9、进入角色池,选几个失配男适配女
10、打开阅读app,朗读,设置转发器,读个几分钟
11、打开multitts,进入角色池,右侧分配表,调一下自己喜欢的声音。
12、也可以单独给几个特别的角色匹配声音。
1、在左上角菜单中倒数第三行打开『转发服务』;
2、在软件设置-播放设置中打开『流式传输』;
3、在软件设置-其他设置中点击『添加至阅读』,然后点确定(需要安装“阅读”APP);
4、进入“阅读”APP,打开一本书,开始朗读,在朗读设置中将“阅读引擎”设置为『MultiTTS转发器』。
以上设置的效果是,段落与段落之间的阅读几乎无间隔。理论上“流式传输”已经可以减少段落之间朗读的间隔,但使用“转发器”则可以将这个间隔减少到几乎为0。
共存版:签名不同,可同时安装使用,当你对现有版本满意,且对新版本的新功能和稳定性存疑时,可先尝试安装共存版本,满意后再同签名版本升级。
单击选择/取消选择主合成引擎
长按选择/取消选择对话合成引擎
长按头像编辑发音人
长按已下载图标删除发音人
按住发音人名称上下拖动排序
按住发音人名称左右滑动删除
其他列表,左右滑动删除,上下拖动排序
主界面在列表顶部下拉,显示批量管理界面
导入数据:选择包含受支持引擎数据的压缩包导入,要求压缩包第一层必须包含合法的config.yaml。
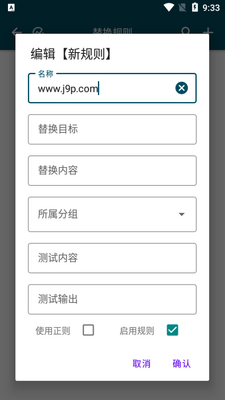
编辑替换:可在此界面中纠正单词读音,支持普通替换和正则替换。
背景音乐:在合成语音的同时,播放背景音。
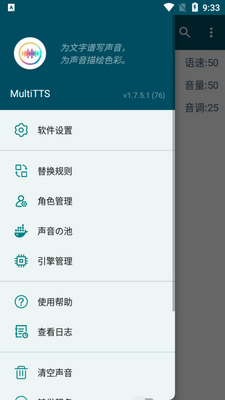
角色管理:添加规则,识别朗读文本中的角色,并用指定的发音人进行朗读。
声音の池:对于每个匹配抽象角色的具体人物,会从声音池中选出一个声音分配给该人物。
引擎管理:对引擎进行编辑、添加、删除、排序和导出数据。
重载数据:重新读取配置文件并加载数据,默认从数据库中加载。
角色名称:要匹配角色的名称。
角色正则:匹配角色名的正则表达式,不填写时使用角色名称的值。
抽象角色:不启用时,所有匹配的人物都将使用同一个声音;启用时,表示这是一个抽象角色(对应多个具体人物),每个具体人物将从声音池中抽取一个声音分配。
前向匹配:规则将匹配对话前的文本。
后向匹配:规则将匹配对话后的文本。
文本:匹配符合正则表达式的全部文本内容
语言:匹配符合选中语言的文本
角色:匹配对话内容的说话者
角色管理界面,长按添加按钮以添加候选语种发音人。
软件会先进行所有前向匹配,在前向匹配没有结果时,才会进行后向匹配。
类型:引擎类型,目前仅支持添加http引擎。
代号:引擎的内部表示,请使用字母数字和下划线。
请求头:发送http请求时使用的请求头。
URL:http链接,java script表达式请用{{}}包裹。
voiceCode:发音人代号
speakText:要合成的文本
speakSpeed:语速,取值0~100
speakVolume:音量,取值0~100
params:参数数组,对应发音人的参数,已进行分割
抽象角色:角色管理中定义的抽象角色。
角色声音:抽象角色对应的每个具体人物,将从同一分组下的声音中选出一个分配给它。
角色匹配规则:用于匹配对话角色时,过滤出合法的上下文。用__ROLE__指代要匹配的角色,__OTHER__指代其他角色。
语法结构分析:输入一段文本,对文本进行词性标注,获取句子语法结构。词性表请参见帮助末尾。
自动分配声音:识别到人物后,自动从角色池选择声音分配(需要先定义抽象角色和设置好角色池)。分配关系将被缓存,直至被新记录覆盖。
文本人物分析:分析文本中出现的新词,分析过程较长。分析完成后,点击保存,将在角色管理中生成角色。
人物名称正则:用于在文本人物分析中,对分析出的新词进行筛选,以过滤出人名。
语音合成接口( http://localhost:8774/forward ),GET参数:
text:要合成的文本
speed:语速,取值0~100
volume:音量,取值0~100
pitch:音高,取值0~100
voice:声音id,请求/voices接口获取所有发音人
语音列表接口( http://localhost:8774/voices ),无参数。
如需在文本中手动指定说话人,可在对话内容引号内部用<<>>包裹人名。示例:“<<张三>>这句话是我说的。”
如果应用被杀后台,请设置电池优化、后台运行、关联启动、阻止休眠(视手机而定)等权限。
导入压缩包时如果错误信息包含zip关键字,可能是下载压缩包时出错。
软件崩溃时,会将日志复制到剪贴板,反馈问题时请附上完整日志。
文本转语音:
将文本内容转换为语音朗读,支持多种格式的文本文件,如TXT、PDF、EPUB等,方便用户在阅读时选择语音朗读。
语音包管理:
用户可以自由下载和管理不同的AI语音包,根据自己的需求选择合适的音色和语种。
离线下载:
支持语音包的离线下载,用户可以在有网络的情况下提前下载所需的语音包,之后在离线状态下也能正常使用。
音色切换:
用户可以在不同的语音包之间自由切换,随时调整音色,以适应不同的阅读场景和个人喜好。
朗读控制:
提供播放、暂停、快进、倒退等基本控制功能,用户可以轻松控制朗读进度,还可以调整语速和音量。
数据重载:
如果在覆盖更新后不显示发音人,用户可以通过点击右上角的菜单栏选择“重载数据”来恢复正常的语音包显示。
修复一些问题。
更新Sherpa-onnx库,现在支持matcha和kokoro类型的模型。但目前sherpa-onnx对kokoro多语言模型的支持还存在一些问题。
添加印尼语翻译,由novan Galaxy提供。
更新俄语翻译,由Frost & Pallado提供。
multitts语音包下载:https://pan.baidu.com/s/1FX9U841Kqmprkaj5IU7GwA?pwd=j9p6
语音引擎TTS软件
 百度阅读APP手机版下载8.0.3.0 最新版
百度阅读APP手机版下载8.0.3.0 最新版 图书阅读 / 25.4M / 26-06-17下载
图书阅读 / 25.4M / 26-06-17下载  懒人畅听车载版2026v2.2.0 最新版
懒人畅听车载版2026v2.2.0 最新版 图书阅读 / 13.8M / 21-04-23下载
图书阅读 / 13.8M / 21-04-23下载  懒人畅听大字版官方版1.0.0 手机版图书阅读 / 19.7M / 21-04-23下载
懒人畅听大字版官方版1.0.0 手机版图书阅读 / 19.7M / 21-04-23下载  小悟故事app解锁VIP版v2.4.500 最新版图书阅读 / 109.7M / 24-09-14下载
小悟故事app解锁VIP版v2.4.500 最新版图书阅读 / 109.7M / 24-09-14下载  QQ阅读官方版8.5.2.666 安卓版图书阅读 / 119.2M / 26-06-23下载
QQ阅读官方版8.5.2.666 安卓版图书阅读 / 119.2M / 26-06-23下载  财经杂志APP安卓7.4.0 手机最新版图书阅读 / 49.8M / 26-06-16下载
财经杂志APP安卓7.4.0 手机最新版图书阅读 / 49.8M / 26-06-16下载  追书神器App下载4.86.8 安卓最新版图书阅读 / 78.2M / 26-06-05下载
追书神器App下载4.86.8 安卓最新版图书阅读 / 78.2M / 26-06-05下载  简书app官方版v6.8.2手机最新版图书阅读 / 49.7M / 25-11-01下载
简书app官方版v6.8.2手机最新版图书阅读 / 49.7M / 25-11-01下载  爱奇艺叭嗒漫画软件v5.9.6 官方最新版图书阅读 / 106.5M / 25-07-14下载
爱奇艺叭嗒漫画软件v5.9.6 官方最新版图书阅读 / 106.5M / 25-07-14下载  咚漫漫画高级免费专业版V2.8.9 免登录版图书阅读 / 68.5M / 23-02-03下载
咚漫漫画高级免费专业版V2.8.9 免登录版图书阅读 / 68.5M / 23-02-03下载  qq下载2026最新版
qq下载2026最新版 抖音极速版app正版
抖音极速版app正版 百度地图app手机最新版
百度地图app手机最新版 快手2026最新版官方正版
快手2026最新版官方正版 Google语音服务app助手20250623.02 最新版
Google语音服务app助手20250623.02 最新版 TTS语音助手app2.0.1 免费版
TTS语音助手app2.0.1 免费版 犀牛语音助手车机版1.3 官方版
犀牛语音助手车机版1.3 官方版 至尊语音助手app高级版v1.8.5.3安卓免费版
至尊语音助手app高级版v1.8.5.3安卓免费版 文本转语音(Text To Speech)1.2.6 专业免费
文本转语音(Text To Speech)1.2.6 专业免费 名阳文字转语音app高级版v2.0.27免费去广告
名阳文字转语音app高级版v2.0.27免费去广告 微软TTS语音朗读app新版0.2_202212201955 安
微软TTS语音朗读app新版0.2_202212201955 安 逃兔语音助手1.0.3安卓版
逃兔语音助手1.0.3安卓版 tts语音合成助手app免金币v2.0.11免费版
tts语音合成助手app免金币v2.0.11免费版 咩咩语音助手1.8.5.2版免激活版
咩咩语音助手1.8.5.2版免激活版








 Adobe Acrobat Reader阅读器
Adobe Acrobat Reader阅读器 喜马拉雅极速版app
喜马拉雅极速版app 热门小说大全app
热门小说大全app